| function_call_demo | ||
| guides | ||
| interpreter_demo | ||
| langchain_demo | ||
| llamaindex_demo | ||
| metric | ||
| repodemo | ||
| resources | ||
| web_demo | ||
| LICENSE | ||
| MODEL_LICENSE | ||
| README_zh.md | ||
| README.md | ||
![]()
🏠 Homepage|🛠 Extensions VS Code, Jetbrains|🤗 HF Repo | 🪧 HF DEMO
CodeGeeX4: Open Multilingual Code Generation Model
We introduce CodeGeeX4-ALL-9B, the open-source version of the latest CodeGeeX4 model series. It is a multilingual code generation model continually trained on the GLM-4-9B, significantly enhancing its code generation capabilities. Using a single CodeGeeX4-ALL-9B model, it can support comprehensive functions such as code completion and generation, code interpreter, web search, function call, repository-level code Q&A, covering various scenarios of software development. CodeGeeX4-ALL-9B has achieved highly competitive performance on public benchmarks, such as BigCodeBench and NaturalCodeBench. It is currently the most powerful code generation model with less than 10B parameters, even surpassing much larger general-purpose models, achieving the best balance in terms of inference speed and model performance.
Model List
| Model | Type | Seq Length | Download |
|---|---|---|---|
| codegeex4-all-9b | Chat | 128K | 🤗 Huggingface 🤖 ModelScope 🟣 WiseModel |
Get Started
Use 4.39.0<=transformers<=4.40.2 to quickly launch codegeex4-all-9b:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("THUDM/codegeex4-all-9b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/codegeex4-all-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
inputs = tokenizer.apply_chat_template([{"role": "user", "content": "write a quick sort"}], add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True ).to(device)
with torch.no_grad():
outputs = model.generate(**inputs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Use vllm==0.5.1 to quickly launch
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# CodeGeeX4-ALL-9B
# max_model_len, tp_size = 1048576, 4
# If OOM,please reduce max_model_len,or increase tp_size
max_model_len, tp_size = 131072, 1
model_name = "codegeex4-all-9b"
prompt = [{"role": "user", "content": "Hello"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# If OOM,try using follong parameters
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
Set up OpenAI Compatible Server via vllm using following command, detailed please check OpenAI Compatible Server Via vllm docs
python -m vllm.entrypoints.openai.api_server \
--model THUDM/codegeex4-all-9b \
--trust_remote_code
Tutorials
CodeGeeX4-ALL-9B provides three user guides to help users quickly understand and use the model:
-
System Prompt Guideline: This guide introduces how to use system prompts in CodeGeeX4-ALL-9B, including the VSCode extension official system prompt, customized system prompts, and some tips for maintaining multi-turn dialogue history.
-
Infilling Guideline: This guide explains the VSCode extension official infilling format, covering general infilling, cross-file infilling, and generating a new file in a repository.
-
Repository Tasks Guideline: This guide demonstrates how to use repository tasks in CodeGeeX4-ALL-9B, including QA tasks at the repository level and how to trigger the aicommiter capability of CodeGeeX4-ALL-9B to perform deletions, additions, and changes to files at the repository level.
These guides aim to provide a comprehensive understanding and facilitate efficient use of the model.
Evaluation
CodeGeeX4-ALL-9B is ranked as the most powerful model under 10 billion parameters, even surpassing general models several times its size, achieving the best balance between inference performance and model effectiveness.
| Model | Seq Length | HumanEval | MBPP | NCB | LCB | HumanEvalFIM | CRUXEval-O |
|---|---|---|---|---|---|---|---|
| Llama3-70B-intruct | 8K | 77.4 | 82.3 | 37.0 | 27.4 | - | - |
| DeepSeek Coder 33B Instruct | 16K | 81.1 | 80.4 | 39.3 | 29.3 | 78.2 | 49.9 |
| Codestral-22B | 32K | 81.1 | 78.2 | 46.0 | 35.3 | 91.6 | 51.3 |
| CodeGeeX4-All-9B | 128K | 82.3 | 75.7 | 40.4 | 28.5 | 85.0 | 47.1 |
CodeGeeX4-ALL-9B scored 48.9 and 40.4 for the complete and instruct tasks of BigCodeBench, which are the highest scores among models with less than 20 billion parameters.
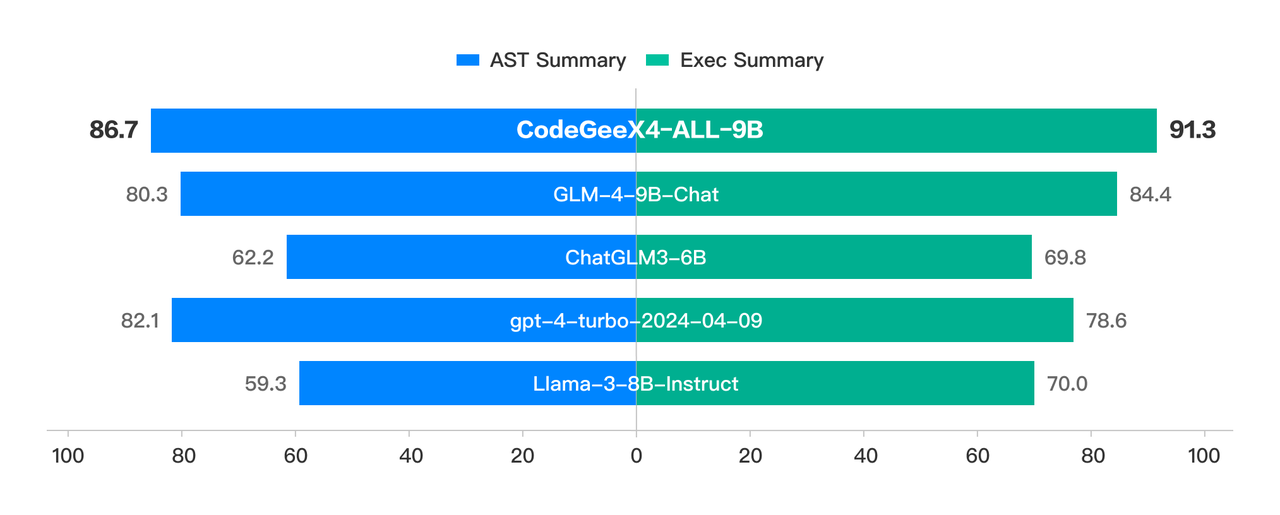
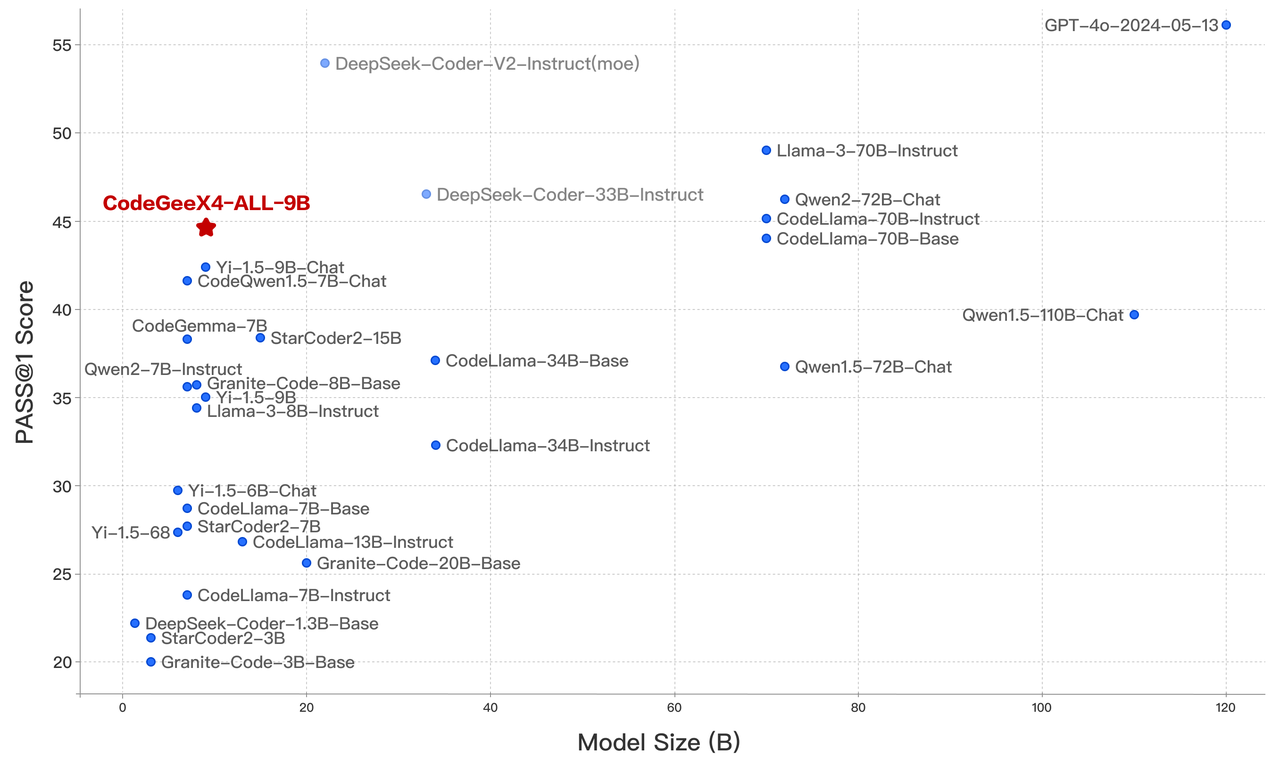 In CRUXEval, a benchmark for testing code reasoning, understanding, and execution capabilities, CodeGeeX4-ALL-9B presented remarkable results with its COT (chain-of-thought) abilities. From easy code generation tasks in HumanEval and MBPP, to very challenging tasks in NaturalCodeBench, CodeGeeX4-ALL-9B also achieved outstanding performance at its scale. It is currently the only code model that supports Function Call capabilities and even achieves a better execution success rate than GPT-4.
In CRUXEval, a benchmark for testing code reasoning, understanding, and execution capabilities, CodeGeeX4-ALL-9B presented remarkable results with its COT (chain-of-thought) abilities. From easy code generation tasks in HumanEval and MBPP, to very challenging tasks in NaturalCodeBench, CodeGeeX4-ALL-9B also achieved outstanding performance at its scale. It is currently the only code model that supports Function Call capabilities and even achieves a better execution success rate than GPT-4.
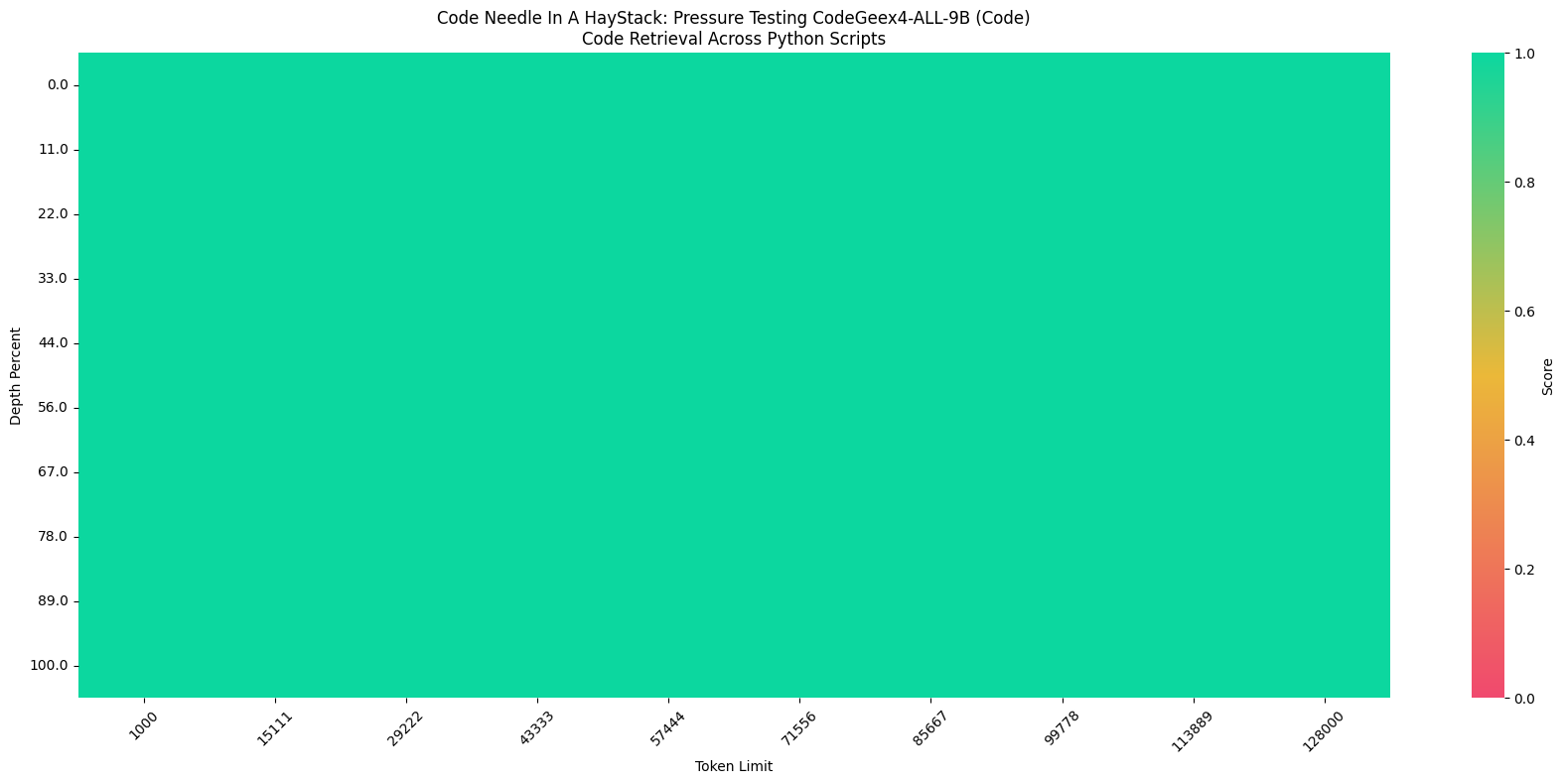
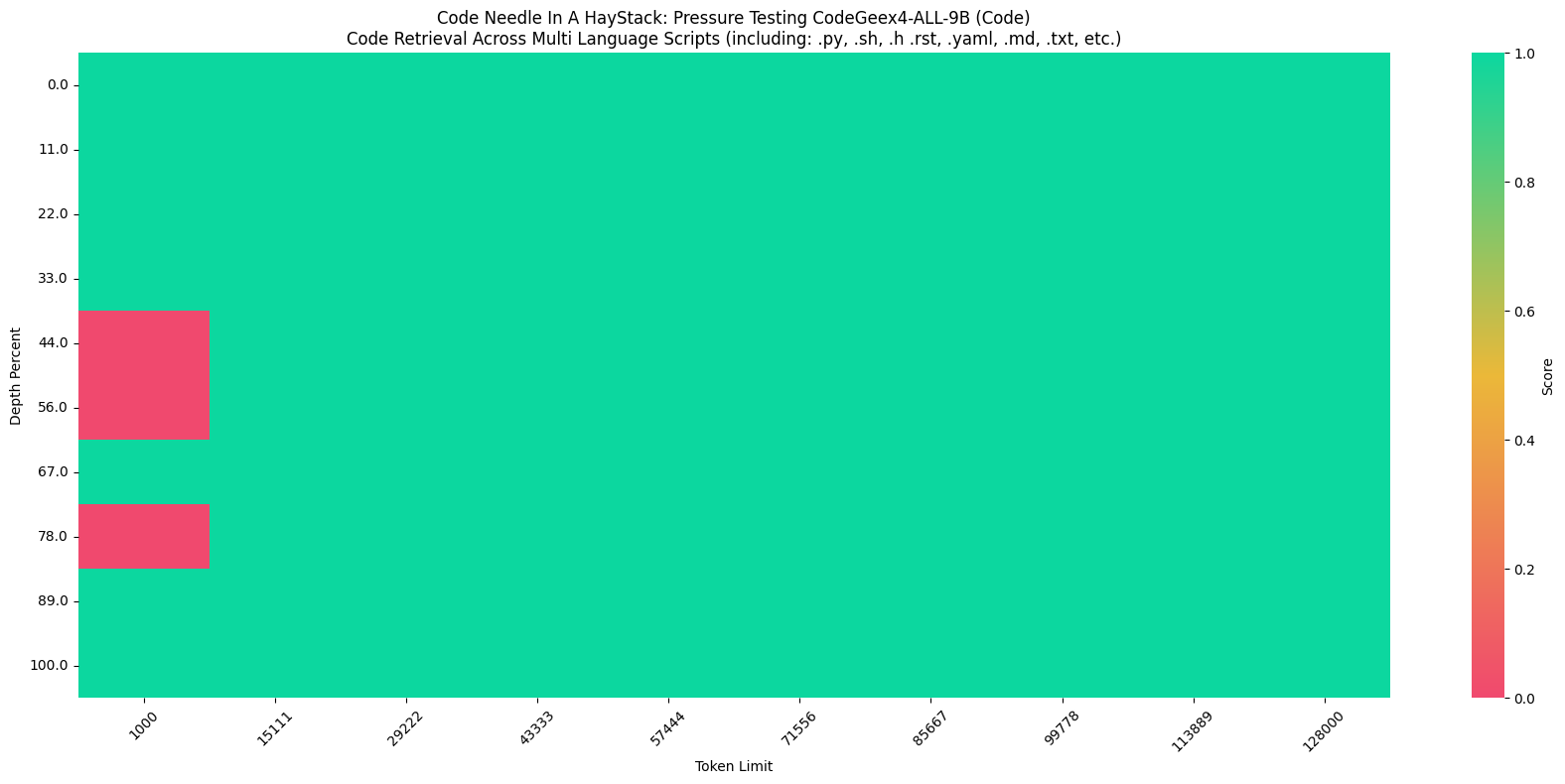
 Furthermore, in the "Code Needle In A Haystack" (NIAH) evaluation, the CodeGeeX4-ALL-9B model demonstrated its ability to retrieve code within contexts up to 128K, achieving a 100% retrieval accuracy in all python scripts.
Furthermore, in the "Code Needle In A Haystack" (NIAH) evaluation, the CodeGeeX4-ALL-9B model demonstrated its ability to retrieve code within contexts up to 128K, achieving a 100% retrieval accuracy in all python scripts.
Details of the evaluation results can be found in the Evaluation.
License
The code in this repository is open source under the Apache-2.0 license. The model weights are licensed under the Model License. CodeGeeX4-9B weights are open for academic research. For users who wish to use the models for commercial purposes, please fill in the registration form.
Citation
If you find our work helpful, please feel free to cite the following paper:
@inproceedings{zheng2023codegeex,
title={CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X},
author={Qinkai Zheng and Xiao Xia and Xu Zou and Yuxiao Dong and Shan Wang and Yufei Xue and Zihan Wang and Lei Shen and Andi Wang and Yang Li and Teng Su and Zhilin Yang and Jie Tang},
booktitle={KDD},
year={2023}
}